
Claude Limits Are Real. Here’s the Workflow I Built So They Don’t Matter
Mar 24, 2026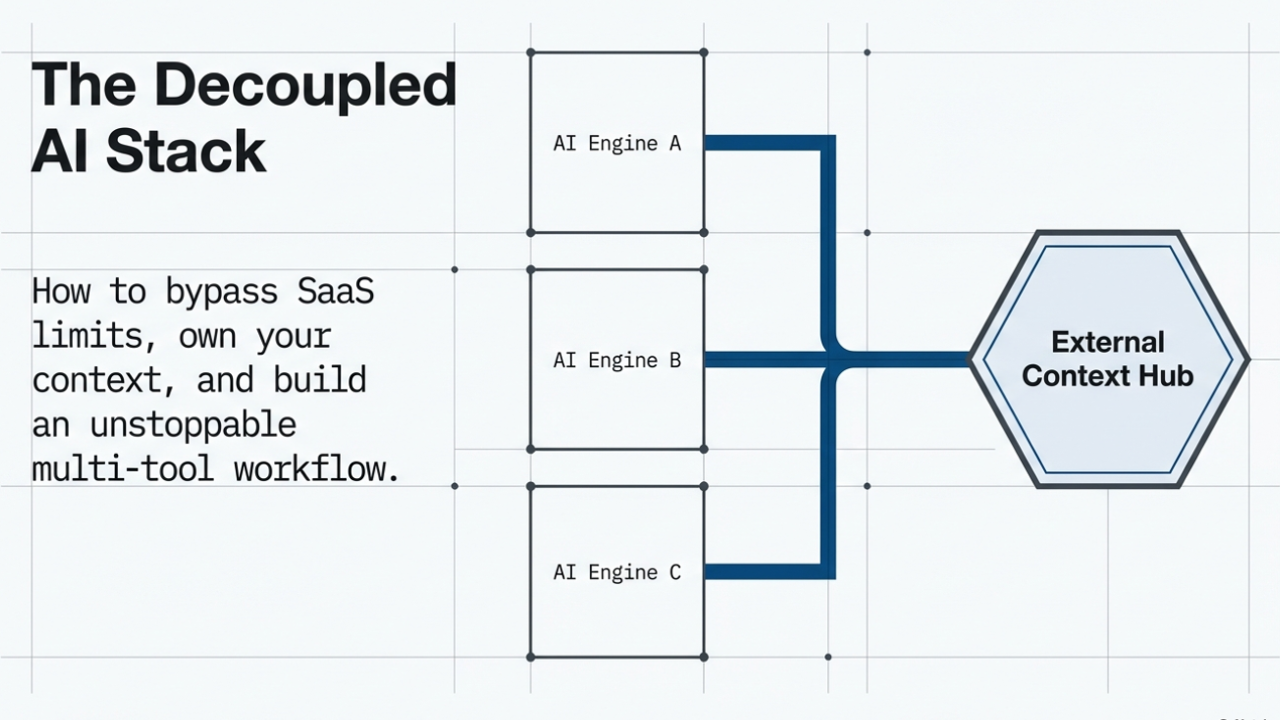
Over the past days, more and more developers have been talking about Claude limits. Not in the abstract sense of "AI is expensive" or "SaaS companies change pricing", but in the very practical sense of sitting down to do serious work, getting into flow, and then suddenly being told to stop. What stood out to me was not only the volume of complaints, but the pattern behind them. Many people were clearly no longer using Claude as a chat interface. They were using it as a real working environment, especially through Claude Code, and that changes what a limit actually means.[1]
One Reddit thread that became a kind of collection point for this frustration explicitly framed the issue as "measurable" and "widespread", and linked to a broader cluster of related posts, GitHub issues, and social posts from users who believed something had changed in practice, even if the pricing page itself had not.[2] I do not think community threads are proof on their own, and I would never treat them as a substitute for vendor documentation. But they are still useful as field evidence. They show what people are experiencing, what they are comparing against, and what kind of work is now being interrupted.
Anthropic's own help center is clear on one important point: usage is shared across Claude and Claude Code for Pro and Max plans.[1] Anthropic also ran a March 2026 promotion that temporarily doubled five-hour usage during off-peak hours across multiple Claude surfaces, including Claude Code.[3] Put differently, the company itself is openly acknowledging that usage capacity is something dynamic, managed, and operationally relevant. That does not prove any specific bug. But it does provide important context for why the current discussion feels so intense.
So yes - the limits are real. But I do not think the most interesting question is whether they are fair. The more interesting question is why so many of us have built workflows that stop completely the moment one SaaS tool becomes unavailable.
The uncomfortable truth about SaaS tools
This was the part that shifted my thinking the most. When we use SaaS tools, we are operating inside someone else's system. The provider decides how plans are structured, how usage is measured, which capabilities are bundled, what gets rate-limited, and how much flexibility power users actually have in practice. We can disagree with those choices, and sometimes we absolutely should. But the basic model does not change: we are still building on top of infrastructure we do not control.
That is why I increasingly think that endless public outrage about limits misses the more important design question. Complaining may be emotionally justified, especially when communication is poor or expectations are unclear. But it does not solve the underlying fragility. If one vendor, one product surface, or one plan change can interrupt the whole chain of work, then the workflow itself is too dependent on that tool.
The real problem is not that SaaS providers have limits. The real problem is building a workflow that collapses when those limits appear.
For me, that became the key insight. I stopped asking, "Why are they doing this?" and started asking, "How do I build in a way where this no longer matters so much?" That changed the tone of the problem immediately. It stopped being mainly emotional and became architectural.
Why my perspective on this is different
I am not looking at this as someone who occasionally opens a chat window to generate a quick snippet or summarize an article. I work across customer projects, technical prototypes, automation ideas, domain-driven side projects, and longer-term product directions. I also think about these tools not only as user interfaces, but as parts of a delivery system. That matters because the more serious the work becomes, the more dangerous it is to confuse a convenient tool with a durable operating model.
This is also why I write about topics like OpenClaw, agent runtimes, workflow design, automation, and enterprise AI from a slightly different angle. I am less interested in hype cycles and more interested in operational consequences. What happens when a tool becomes part of your real workflow? What happens when it starts carrying context, continuity, and execution across multiple efforts at once? What happens when the friction becomes low enough that you start routing actual work through it, not just experiments?
Once you ask those questions, usage limits stop being a consumer annoyance and start looking more like an infrastructure constraint.
What changed for me: I stopped storing thinking inside the AI tool
The biggest practical change in my own workflow was surprisingly simple. I stopped treating Claude, Claude Code, Copilot, Kiro, or any other assistant as the place where project memory should live.
Instead, the memory now lives in Notion.
And I do not mean only final documentation or polished project pages. I mean the messy but useful middle of the work. Why a repository exists. Which direction I rejected. Which architecture decision was made. What still needs to be checked. Which prompts produced useful output. What should be continued later. Which open questions are still unresolved. In other words, the kinds of notes that are usually trapped inside a thread and then slowly disappear into chat history.
This matters because once the thinking is externalized, the assistant is no longer the memory. It becomes an execution interface that can work with a memory layer I control. That is a fundamentally different relationship. The tool becomes useful without becoming the container of the work.
In my setup, that memory layer is accessible through Notion MCP, which means other assistants can work with the same structured context. That is what makes tool switching realistic rather than theoretical. It is not "I vaguely remember what I was doing and hope the next assistant can reconstruct it." It is "the reasoning, decisions, and next steps already exist outside the original thread."
Claude Code remote control changed the situation much more than I expected
One feature that made this workflow feel immediately more powerful was Claude Code's remote control capability. Anthropic documents that remote control can continue local sessions from another device, carry over current conversation history, and even allow users to access sessions from a browser or the Claude app.[4] In addition, the documentation describes modes such as shared-directory sessions and git worktree-based sessions, which makes it clear that this is not merely a toy mobile companion feature. It is part of a broader shift toward remote, session-based execution.[4]
For me, the significance was not just technical. It was behavioral. I had accumulated domains and project ideas over the years that I genuinely cared about, but which often remained untouched because they seemed to require a full context switch. I thought of them as "projects I will work on properly later", which is often another way of saying "projects that remain in limbo".
Remote control changed that. Suddenly, I could be on the couch, or already working through customer tasks, or moving between other priorities, and still continue the same thread from my phone while my laptop handled the actual work. That reduced a huge amount of friction. It made it much easier to create repositories, sketch structures, capture ideas, generate first documentation, and move things from vague intention to real artifacts.
That is also where the comparison to OpenClaw became interesting for me. In my earlier post on OpenClaw, I described the appeal of local agent runtimes as being less about "chat" and more about execution under the user's control. But once Claude Code remote control exists, some of the experiential gap becomes smaller. It starts to feel less like "cloud chat" and more like directing a session that can act on a real machine.[4]
The difference, at least for me, is no longer mainly about whether one can execute structured work and the other cannot. That distinction has blurred. The more relevant distinction is operational control. OpenClaw runs locally. Claude Code is a managed SaaS environment. But in practical day-to-day usage, remote control means the managed environment now reaches much further into actual execution than many people still assume.
What happened when I hit the Max plan limits
Then came the point where all of this stopped being a conceptual discussion and became very concrete.
Despite paying for Max, I hit the limits after roughly two hours of focused work. I waited, came back, continued, and then hit them again after about 45 minutes. If I had been using Claude in a light chat-oriented way, that would already have been frustrating. But I was not using it like that at all.
During that time, I created around 50 to 60 repositories, worked across many different project ideas, and generated hundreds of commits. This was not one linear coding sprint in one codebase. It was broad execution across a backlog of domains, structures, and related tasks. In other words, I was treating Claude Code less like a prompt box and more like an execution layer across multiple parallel initiatives.
That is why the current complaint pattern is so interesting. The Reddit threads are not only expressions of irritation. They are also signals that usage behavior is changing. People are increasingly using these systems as workflow infrastructure, not merely as assistants for occasional questions.[2] Once that happens, a limit is no longer experienced as "I should take a break". It is experienced as "a key execution surface has become unavailable".
To be clear, Anthropic's documentation does not promise unlimited use, and it explicitly explains what options exist after a user hits shared Pro or Max limits. Those options include waiting for limits to reset, enabling extra usage, upgrading the plan, or moving into API credit usage for intensive coding sprints.[1] That is the official product framing. My point is not that the documentation is hidden. My point is that the lived experience changes dramatically once the tool becomes deeply embedded in real work.
Switching to Kiro and Copilot was not the backup plan - it was the proof
The most important part of this story is what happened next. Once the Claude limits were reached, the work did not stop.
I continued on the same projects with Kiro and Copilot. And this is exactly why the Notion setup mattered. Because the reasoning context was already externalized and the project state already existed in GitHub, I did not need Claude to remember everything for me. The repos were there. The notes were there. The continuation points were there. Through MCP and shared project context, I could keep moving.
This is where I think many people still underestimate the importance of workflow design. Multi-tool usage only works if the meaningful context has already been moved out of the original tool. Otherwise "switching tools" often means starting over, rewriting the explanation, reconstructing decisions from memory, and losing half the momentum in the process.
Later, when Claude is available again, I can still bring it back in for the kinds of work where I currently prefer it, especially review, restructuring, and other passes where I think it still performs particularly well. That is also important to say honestly. This is not a simplistic "all tools are the same" argument. They are not. The point is not that Claude became irrelevant. The point is that Claude stopped being a single point of failure.
The workaround is not pretending the limits do not exist. The workaround is designing the workflow so that the limits no longer define the boundary of what gets done.
GitHub became the durable execution layer
GitHub played a bigger role in this than it might seem at first. The repositories are not just where code happens to live. They are the durable execution layer of the whole setup. Each repository is a checkpoint any assistant can continue from. Each commit is preserved progress that does not vanish when a context window ends or a session becomes unavailable.
This matters because AI sessions are inherently temporary. They get long. They get rate-limited. They get reset. Tools improve, change, or disappear. But repositories and commits create continuity. One assistant can scaffold, another can refactor, another can review. The work remains inspectable because the actual artifacts live outside the tool.
Once I started looking at GitHub that way, the architecture of the whole workflow became much clearer to me:
- Notion stores the reasoning and decision history.
- GitHub stores the durable project artifacts and versioned progress.
- Assistants become interchangeable contributors instead of becoming the place where the work lives.
Where OpenClaw fits into this picture now
In my previous post, I described OpenClaw as a local-first AI agent that runs on your own machine and executes real tasks through connected tools and permissions. I also argued there that the important distinction is less "chat versus agent" and more "where does the runtime live and who controls it?" That framing still matters to me.
But this post adds an important nuance. I do not think OpenClaw's practical advantage right now is simply that it "can do more". A lot of what makes OpenClaw exciting conceptually can now also be approached through Claude Code, Kiro, Copilot, and other increasingly agent-like coding environments. The real difference is still operational control, not magical capability.
And even that operational advantage needs to be put into perspective. Running things locally sounds attractive in theory, especially if one values independence and direct control. But GPUs are expensive, hardware in general is expensive, memory is expensive, and managing local runtimes has real operational overhead. So I do not currently see "it runs on my own machine" as an automatic practical win for most people. In many cases, it is simply a different trade-off.
What I find more interesting is that the broader market is converging toward the same interaction model. Whether local or managed, we are moving from tools that mainly respond to prompts toward tools that can execute structured work across files, repositories, tasks, and connected systems. That is the larger shift, and it is also why usage limits suddenly feel much more consequential than they did when these systems were mainly being used as advanced chat interfaces.
How much context we are really giving these tools
There is another reason why externalizing memory matters. When we work deeply with coding assistants, we are not just sharing snippets or isolated questions. We are often sharing product ideas, architecture preferences, naming patterns, domain strategies, unfinished concepts, review habits, and the overall structure of what we are trying to build next.
Even if a provider handles data responsibly, that is still a large amount of strategic context to accumulate inside one vendor environment by default. The more serious the work becomes, the more that matters. For me, this is not only about convenience or productivity. It is also about deciding where my long-term project memory should live and how portable I want that memory to be.
Storing that context in Notion gives me a much cleaner separation. I can decide what becomes durable, what remains temporary, what another assistant should see next, and how the work is organized historically. That makes the whole system more resilient and also, frankly, more legible to me as the person who has to continue living with the consequences of all those earlier decisions.
The practical takeaway
The biggest lesson for me is not that one tool is good and another is bad. It is that memory and execution should not be the same thing. Once the reasoning is externalized, tools become easier to swap, progress becomes more durable, and continuity becomes less dependent on the plan, mood, or limits of one specific provider.
That is why I think the current discussion around Claude limits is more important than it looks. It is not only a complaint about one subscription tier. It is evidence that many people have started using these systems as operational layers for real work. And once that happens, workflow design matters much more than brand loyalty.
Claude Code is still one of the best tools I currently use, and I still plan to use it where it is strongest. But I do not want any single assistant to be the foundation of the whole system anymore.
Own the memory. Own the structure. Own the repos. Then use whichever tool is best at that moment.
That is how limits stop being the whole story.
