
Open-Source AI Wiki: Why I Built AI Solutions Wiki
Jul 01, 2026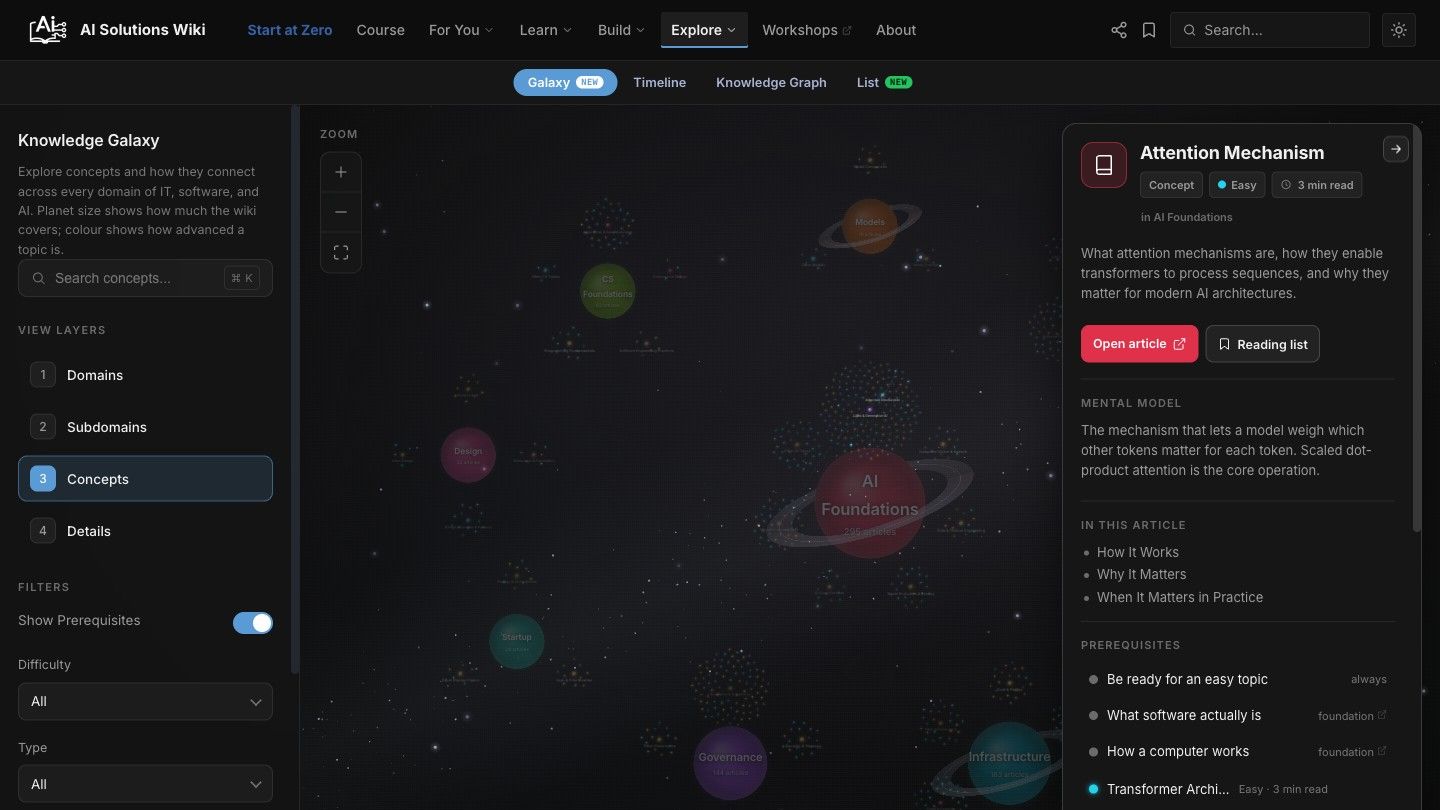
I never planned to build a wiki. I planned to write a few notes.
The honest version is this: IT has never changed as fast as it does right now. Every week brings new tools, renamed services, deprecated APIs, and fresh open-source alternatives. I learn constantly, and I would rather keep what I learn than track it down a second time. No one, however sharp, carries an infinitely large context window in their head. So I decided to build myself one, and the more I learn, the more there is worth keeping.
So I started AI Solutions Wiki: a free, vendor-independent, open-source knowledge base for everything I keep having to look up. This is the second project I am officially publishing. Here is how this one happened, and why it is still beautifully unfinished.
The pace nobody plans for
Every week I get the same questions, from friends, from colleagues, from people in my talks: How do I use this service? Is this still the right tool? Didn't that get renamed? What is the open-source alternative? What is comparable to X? Is this even still maintained?
These are great questions. They are also the exact questions I answer for myself as the field moves. And I noticed something inefficient: I was re-searching things I had already worked out, and asking a chatbot the same question more than once, getting a slightly different answer each time, with no memory of what I had already decided. The knowledge was real. It just was not being kept anywhere.
I wanted one place. A place I trust. A place I curate. So that I do not have to ask a chatbot every time, and so that when a friend asks "what are you actually doing," I can just send a link.
A free, open-source knowledge base about how modern software and AI are actually built: tools, models, comparisons, architecture patterns, a glossary, the history of computing, and the open-source alternatives to the big paid services. It is a static site, so it is fast and costs almost nothing to run. ai-solutions.wiki
So I started writing it down
I did not start with a content plan. I started with myself. I went back through years of my own work: AWS projects, client use cases, conference talks, half-finished notes, things I had explained out loud a hundred times but never written once.
Then I went a layer deeper. For the concepts that actually matter, I tried to do it properly: trace the real origin, find the primary source, the paper or the person who first named the thing, instead of repeating whatever the internet had copied from itself. SOLID is Robert C. Martin, 2000. The Gang of Four design patterns are 1994. Domain-Driven Design is Eric Evans, 2003. REST is Roy Fielding's dissertation, 2000. Where a claim has a source, I want the source on the page.
I will be straight with you: this grows every week, faster than any one person can hand-check line by line. So I lean on sources. Where a claim has an origin, I put it on the page, so you are not trusting me, you are trusting the citation. It is a living resource, and I keep improving it. I would rather tell you it is alive and evolving than pretend it is finished.
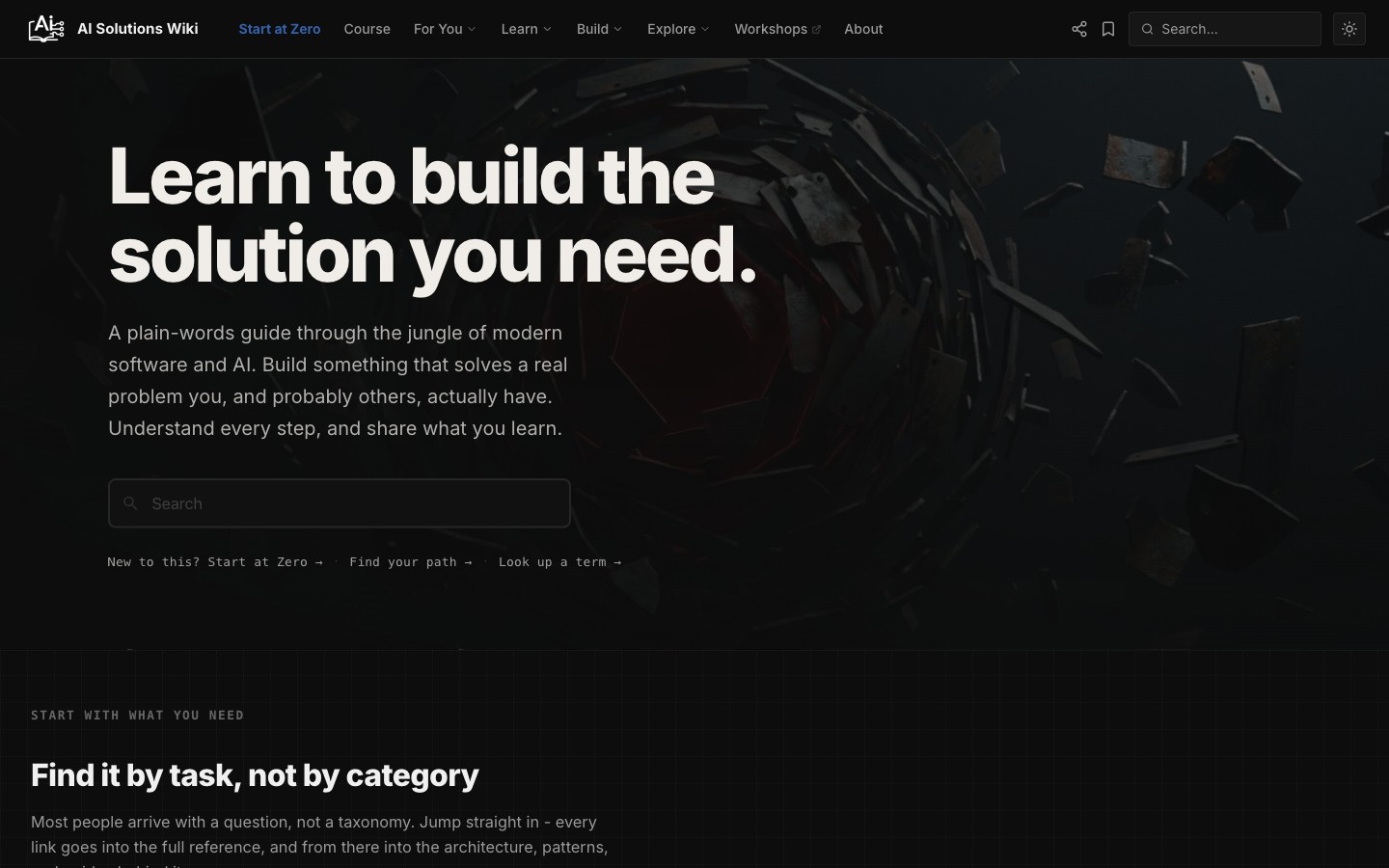 The home page. The whole point is that you do not need to know how to code, but you should understand what is possible.
The home page. The whole point is that you do not need to know how to code, but you should understand what is possible.
What it turned into
What started as a notes dump turned into something I genuinely use. The thing I am proudest of is that you can explore it in whatever way your brain works that day.
If you arrive with a task, the home page now leads with exactly that: trending topics, comparisons, plain-words explainers, and the week's AI news, instead of forcing you to learn my filing system first.
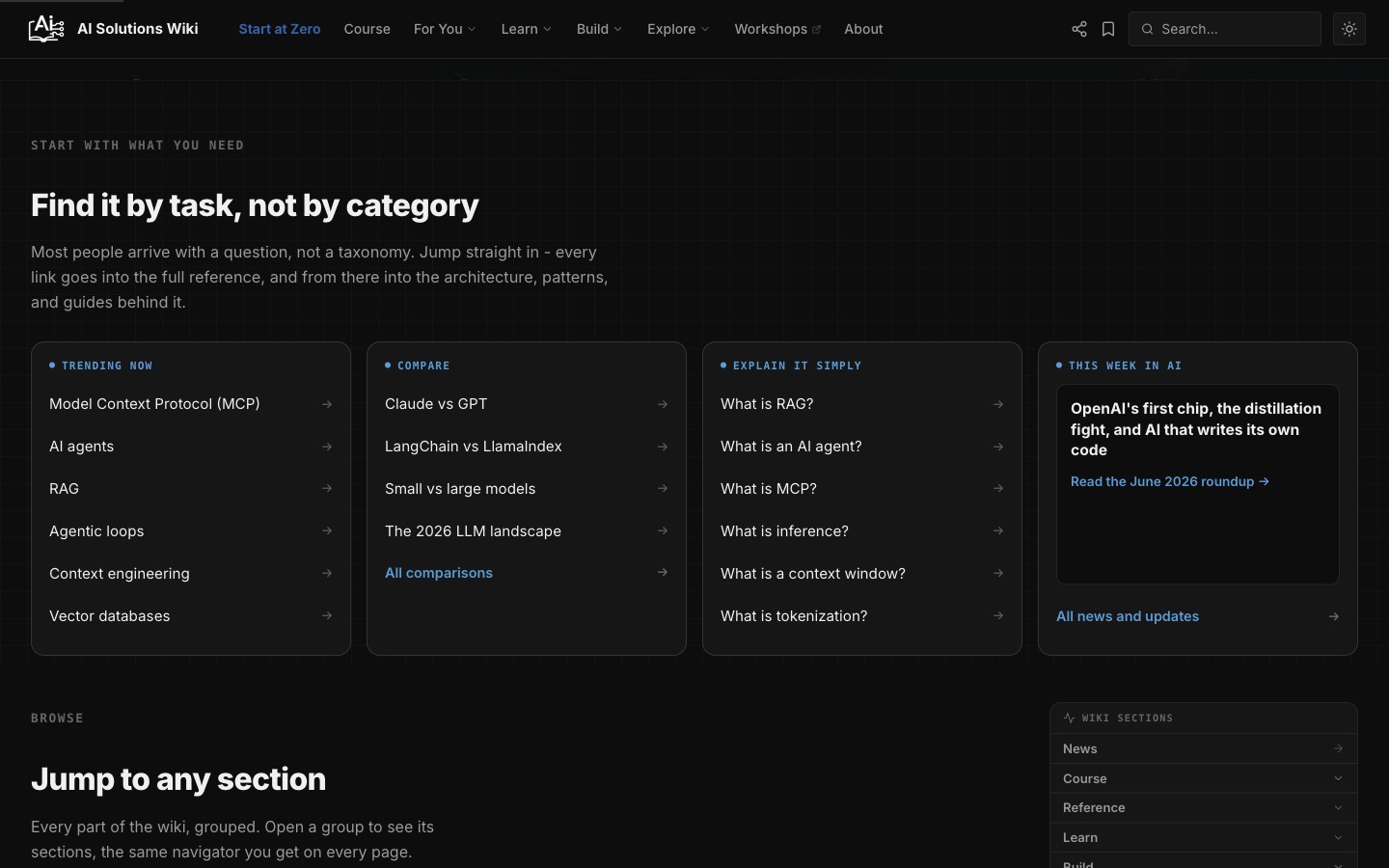 Find it by task, not by category. Most people arrive with a question, not a taxonomy.
Find it by task, not by category. Most people arrive with a question, not a taxonomy.
If you are a visual thinker, there is a Knowledge Galaxy: every domain is a planet, every article a star, and clicking one shows you what to learn first, what it connects to, how long it takes to read, and a mental model in plain words. There is a Timeline of computing from the abacus to agentic systems, and a Knowledge Graph that shows how concepts depend on each other.
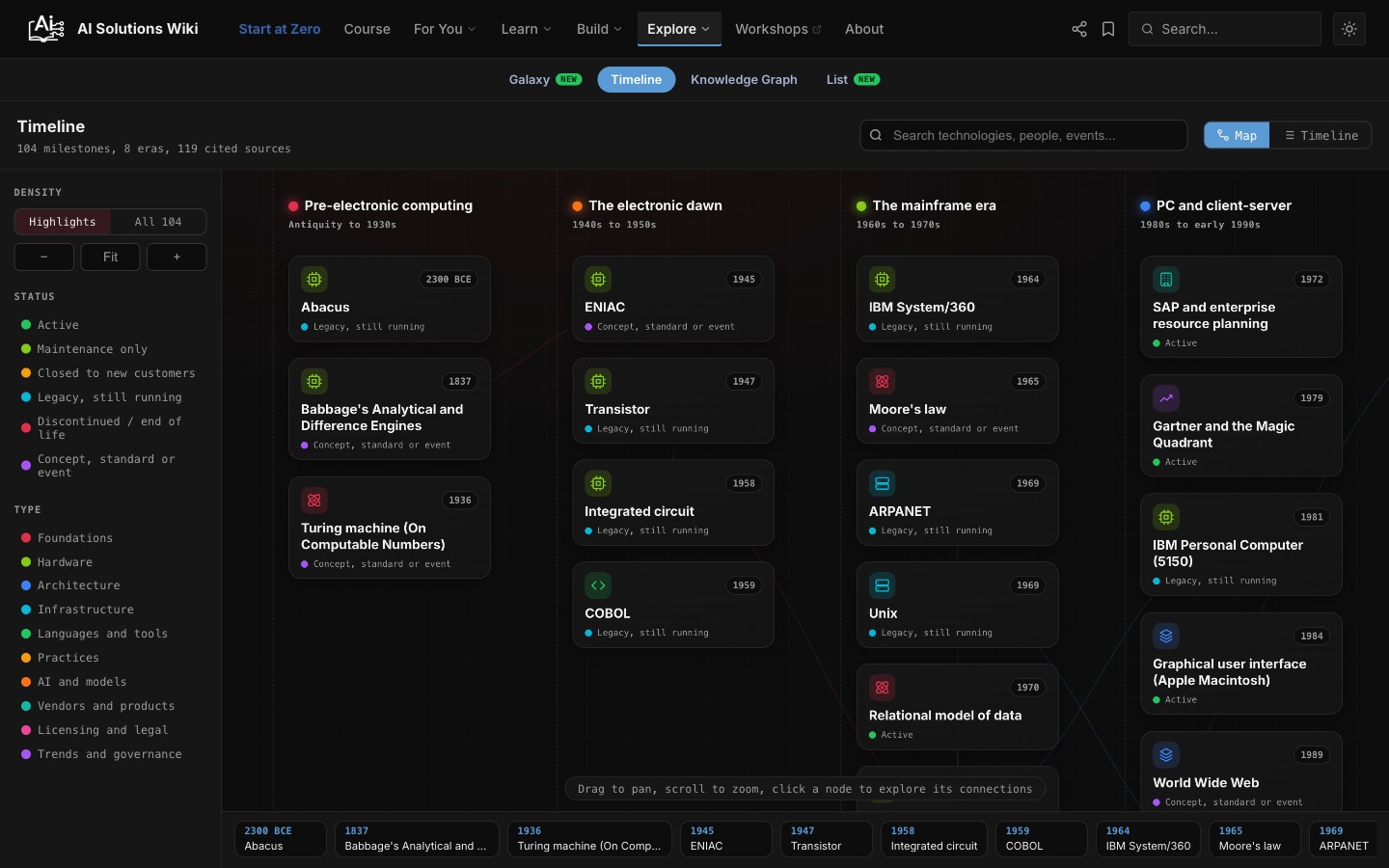 The Timeline. I built this so the history of computing is one click away, instead of a date I have to second-guess.
The Timeline. I built this so the history of computing is one click away, instead of a date I have to second-guess.
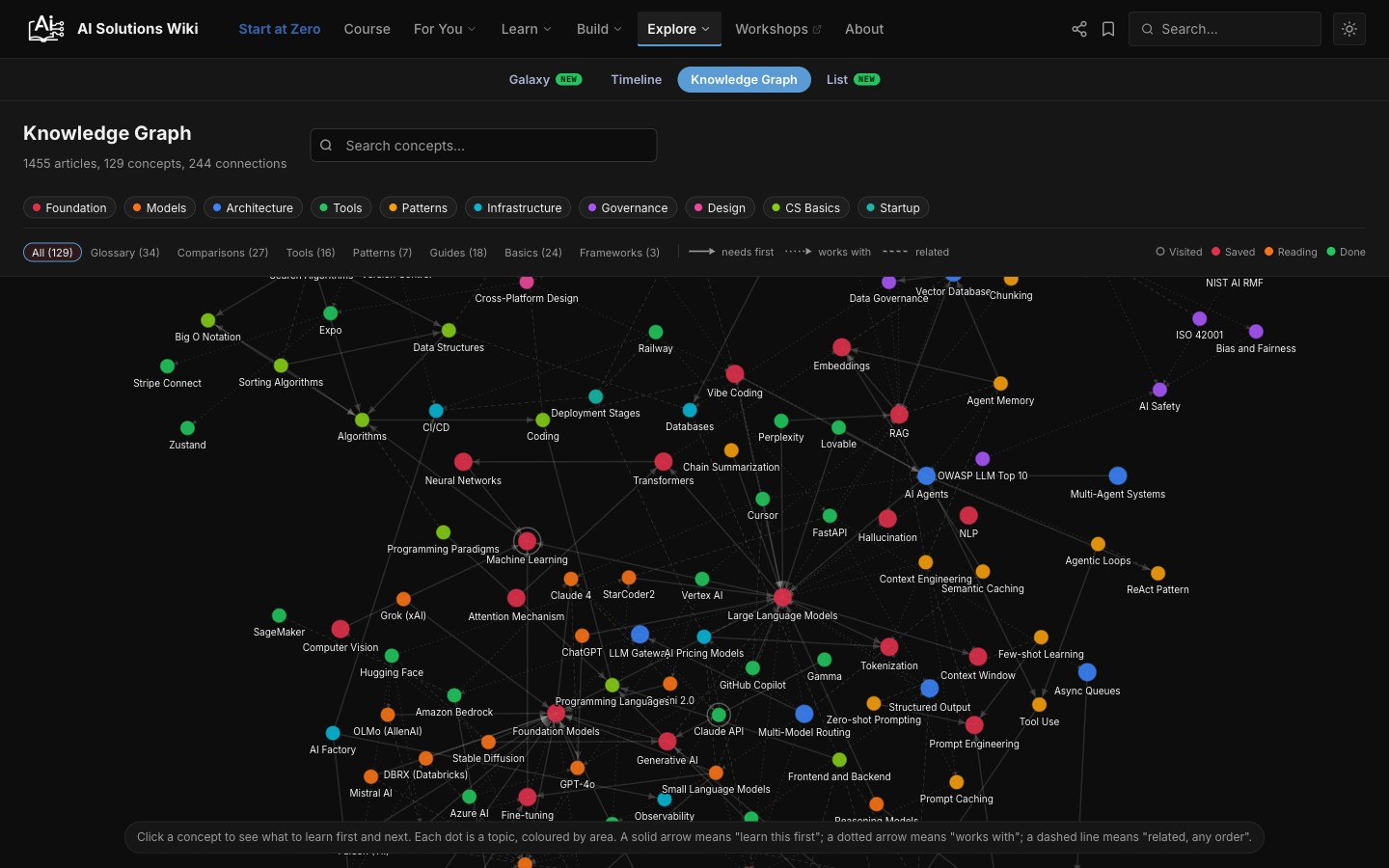 The Knowledge Graph: what to learn first, and what builds on it.
The Knowledge Graph: what to learn first, and what builds on it.
And because the questions I get are so often "what is comparable to X" or "is there an open-source alternative," there is a growing set of comparison pages and a glossary that links everything together. When I write about a principle, I try to say who said it and when, so you can check me.
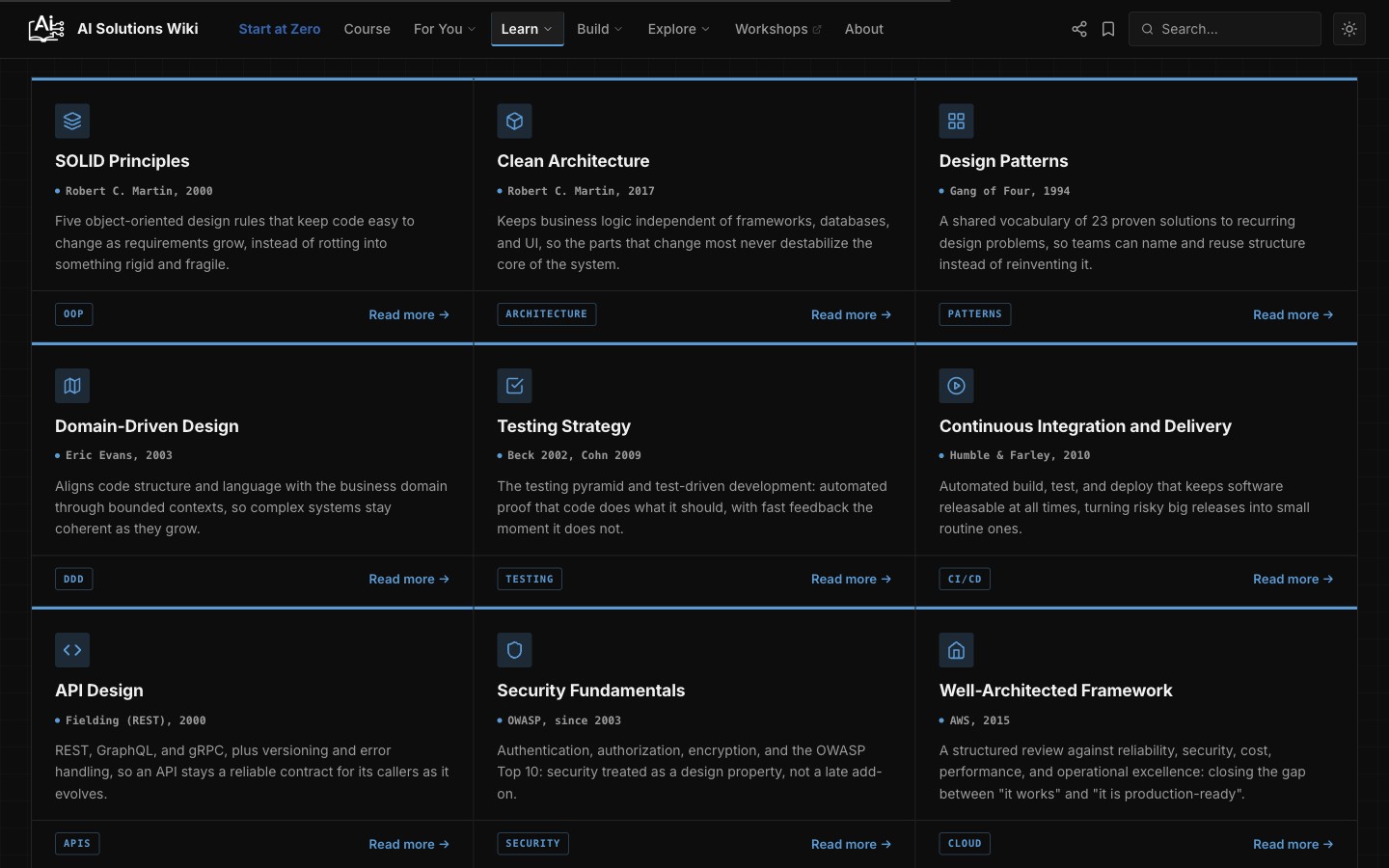 Foundations, with the source and year on every principle. If I claim something is a standard, I want to show who established it.
Foundations, with the source and year on every principle. If I claim something is a standard, I want to show who established it.
How I built it
It is a static site built with Hugo, which means it compiles to plain HTML and CSS, loads fast, and costs almost nothing to host. No framework, no database in production, no server to babysit. The interactive views (the galaxy, the timeline, the graph) are vanilla JavaScript reading from data files I generate from the content itself, so the structure stays honest: if an article exists, it shows up; if it does not, it cannot.
A static site is pre-built into files instead of generated on every request. The upside for a one-person open-source project: it is cheap, fast, and hard to break. The whole thing can be hosted for free and forked by anyone.
I update it at least once a week, usually with the latest AI news turned into something permanent: instead of a story that disappears, each item links into the architecture, tools, and glossary so it becomes part of the map. I use Plausible for analytics, because I want to know what people actually look for without tracking them. And I am building automations around it that I will share as I go.
Here is my favorite detail, and the one that is least rational: for a few days, my repository had organic forks. People I do not know forked it. It is gone now, the counter reset, but I saw it happen, and I will not pretend that did not make my week.
Always growing, on purpose
I want to be clear about what this is. It is a living resource, not a frozen, peer-reviewed encyclopedia. Some pages are already excellent, others are still growing. I add to it a bit at a time, every week, whenever I have some tokens left over, which I am absolutely not giving back, because I am the one paying for them. #tokenmaxxing.
Maybe it stays mostly mine. That would already be worth it, because I use it every day. I send the links to friends to explain what I am actually working on. When someone asks me which service does what, or what replaced the thing that got deprecated, I have somewhere to point them. It saves my time, and it answers, once, the questions I used to answer over and over by hand.
I never want to stop learning, and in this field you cannot afford to. But the boring load-bearing details, the commands, names, years, and syntax, are exactly the things worth keeping rather than carrying in your head. My context window as a human is not infinitely huge, and I am not getting any younger. So this is how I extend it: an external memory where everything I learn is kept, sourced, and connected, so it compounds over time instead of fading. It is my go-to page, and it keeps the knowledge mine.
If you find something wrong, tell me. I genuinely want constructive feedback. The field moves fast and the wiki grows fast, and a second pair of eyes makes it sharper than another paragraph I write at midnight.
Take a look. Fork it. Tell me what is wrong.
AI Solutions Wiki is free and open source. It is the page I actually use, and you are welcome to use it too.
Visit ai-solutions.wikiThis is the second open-source project I am sharing publicly, and there is more coming. I will keep writing about the build, the automations, and the open-source journey along the way. If any of this is useful to you, that is exactly why I made it.
I built an open-source AI wiki because IT has never moved this fast, and I wanted to keep everything I learn instead of relearning it. It started as a tiny side project. It is now the page I open every single day.