
OpenClaw: Der lokale KI-Agent, der Aufgaben erledigt
Feb 24, 2026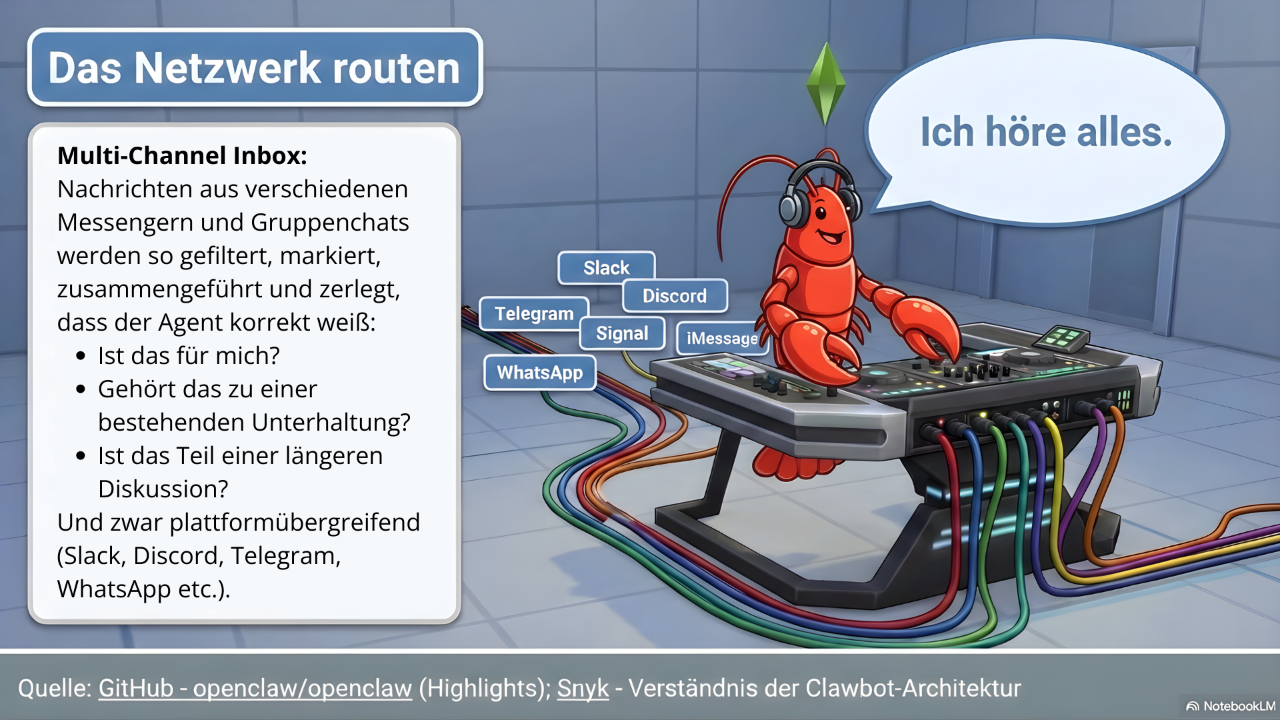
Vor ein paar Wochen hat ein Entwickler-Nebenprojekt in einer einzigen Woche 100.000 GitHub-Stars und 2 Millionen Website-Besucher erreicht.
Keine Werbekampagne. Kein Risikokapital. Kein Produktlaunch-Event. Nur ein Tool, das sich anders anfühlte - und das Internet hat es bemerkt.
Das Projekt heißt OpenClaw. Die öffentliche Namensentwicklung: Clawdbot zuerst, dann Moltbot (27. Januar 2026), dann OpenClaw (29. Januar 2026) - nach einer markenbezogenen Anfrage von Anthropic. („Clawd" taucht im Umfeld des Projekts als früherer interner Name/Maskottchen auf, war aber nicht der öffentlich veröffentlichte Projektname.) Die Kernidee ist seit Tag eins dieselbe.
Das ist mein Versuch, zu erklären, was es wirklich ist - nicht die Hype-Version, nicht die Panik-Version, sondern die sachliche Version.
OpenClaw ist ein local-first KI-Agent, der auf deinem eigenen Computer läuft. Er verbindet sich mit den Messaging-Apps, die du bereits nutzt, und führt echte Aufgaben aus - Dateien, Befehle, APIs - je nachdem, welche Tools und Berechtigungen du aktivierst.

Was macht es anders als ChatGPT oder Claude?
Das ist die entscheidende Frage - aber sie lässt sich heute nicht mehr mit „Chat vs. Agent“ beantworten.
ChatGPT, Claude und Gemini sind längst mehr als reine Chatfenster. Mit bezahlten Zugängen, Desktop-Apps und Agent-Funktionen können sie Aufgaben planen, Tools aufrufen, Code ausführen, Dateien verarbeiten und in begrenztem Umfang auch automatisieren. Man kann eigene Agenten konfigurieren, Workflows definieren und externe Kontexte anbinden.
Der Unterschied liegt nicht darin, was grundsätzlich möglich ist, sondern wo und unter wessen Kontrolle es passiert.
Bei ChatGPT, Claude & Co. laufen Agentenlogik, Tool-Ausführung und Kontextverwaltung zentral in der Cloud der Anbieter. Nutzer:innen steuern Verhalten und Fähigkeiten, betreiben aber keine eigene Laufzeitumgebung. Was der Agent kann, wie lange er „lebt“, welche Tools verfügbar sind und wie stark geloggt wird, ist an Produkt, Plattform und Subscription gebunden. Dafür übernimmt der Anbieter große Teile von Sicherheit, Betrieb und Observability im Rahmen des Shared Responsibility Models - vieles ist einfach da, ohne dass man sich aktiv darum kümmern muss.
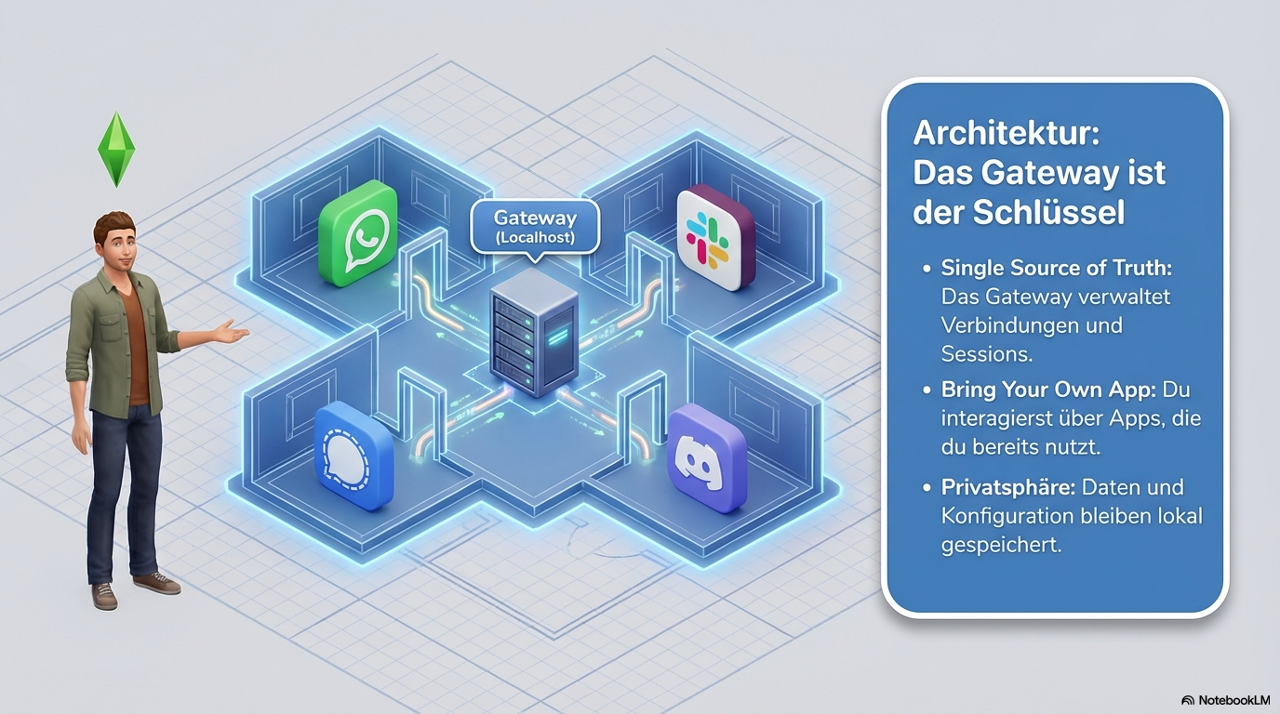
OpenClaw setzt an einer anderen Stelle an. Es ist kein Chatprodukt mit Agent-Features, sondern eine Agenten-Runtime, die lokal oder in eigener Infrastruktur läuft. Das Gateway (Control Plane) läuft auf dem eigenen System, Tools und Skills ebenfalls, und das angebundene Modell ist austauschbar. Ob Cloud- oder lokales Modell, entscheidet der Nutzer.
Der eigentliche Unterschied ist also nicht Fähigkeit, sondern Betrieb und Kontrolle: Wer führt den Agenten aus? Wo laufen die Tools? Wer kontrolliert Berechtigungen, Datenflüsse und Integrationen?
Was dabei leicht unterschätzt wird: Mit dieser Kontrolle verschiebt sich auch die Verantwortung. Logging, Tracing, Dashboards und Sicherheitsmechanismen existieren nicht automatisch - sie müssen aktiv gebaut und betrieben werden. Ohne eigene Observability gilt: Was nicht geloggt wird, ist im Zweifel verloren und nicht nachvollziehbar.
Diese Verschiebung - vom konfigurierten Cloud-Agenten hin zu einer selbst betriebenen Agenten-Laufzeit - ist der Kern dessen, worum es bei OpenClaw eigentlich geht. Auf die praktischen Unterschiede bei Observability, Shared Responsibility und Betrieb gehe ich in einem separaten, ausführlicheren Blogpost ein.
Was daran neu ist (und was nicht)
Es ist wichtig, das einzuordnen: Vieles von dem, was OpenClaw zeigt, war technisch schon vorher möglich. Es gibt seit Jahren Open-Source Multi-Agent-Frameworks, mit denen sich Agenten-Orchestrierung, Tool-Calling, lokale Ausführung und Workflows bauen lassen.
Mit Claude Code, Kiro, GitHub Copilot oder ähnlichen Coding Assistants lassen sich Prototypen, Automationen und ganze Tools bauen - inklusive dem, was heute oft als „vibecoding“ beschrieben wird und sich mittlerweile in eine Spezifikations-getriebene Richtung entwickelt - "spec driven development".
Der Unterschied ist weniger, ob es möglich war, sondern wie zugänglich es war. OpenClaw hat diese Tools und die technischen Möglichkeiten sichtbar gemacht, zusammengeführt und an vielen Stellen einfacher gestaltet.
Das ändert aber nicht, dass es noch Lücken gibt und dass Nutzer weiterhin technisches Verständnis brauchen, um Risiken, Berechtigungen, Modell-Backends und Skill-Code einschätzen zu können.
Trotzdem hat OpenClaw etwas Entscheidendes geschafft: Es hat die Einstiegshürde gesenkt - nicht nur für klassische Entwickler, sondern auch für Menschen mit technischem Verständnis, die bisher keinen direkten Zugang zu lokal gehosteten Open-Source-Frameworks und Coding-Assistant-Workflows hatten.

Woher kommt OpenClaw?
Erstellt wurde es von Peter Steinberger, einem österreichischen Entwickler, bekannt aus der iOS-Open-Source-Community und als Gründer von PSPDFKit (heute Nutrient), einem der meistgenutzten PDF-Frameworks im iOS-Ökosystem. Er hat es Ende November 2025 als Wochenend-Nebenprojekt gebaut - ursprünglich ein WhatsApp-Relay, das eine lokale KI mit einer Messaging-App verband.
Die öffentliche Namensentwicklung: Clawdbot → Moltbot (27. Januar 2026) → OpenClaw (29. Januar 2026). Die Umbenennung zu Moltbot stand in Zusammenhang mit einer markenbezogenen Anfrage von Anthropic - die genauen Details wurden öffentlich nicht vollständig offengelegt. Dann folgte ein Community-Brainstorming, ein Hummer-Maskottchen wurde zur Folklore, und am 29. Januar 2026 landete es bei OpenClaw.
Am 29. Januar 2026, als er den Blogpost „Introducing OpenClaw" veröffentlichte, hatte das Projekt bereits 100.000+ GitHub-Stars. Eine einzige Woche hatte 2 Millionen Besucher gebracht. Ende Februar 2026: rund 222.000 Stars und 42.400+ Forks - eine ungewöhnliche Zahl für ein 90 Tage altes Open-Source-Projekt.

Die vier Bausteine
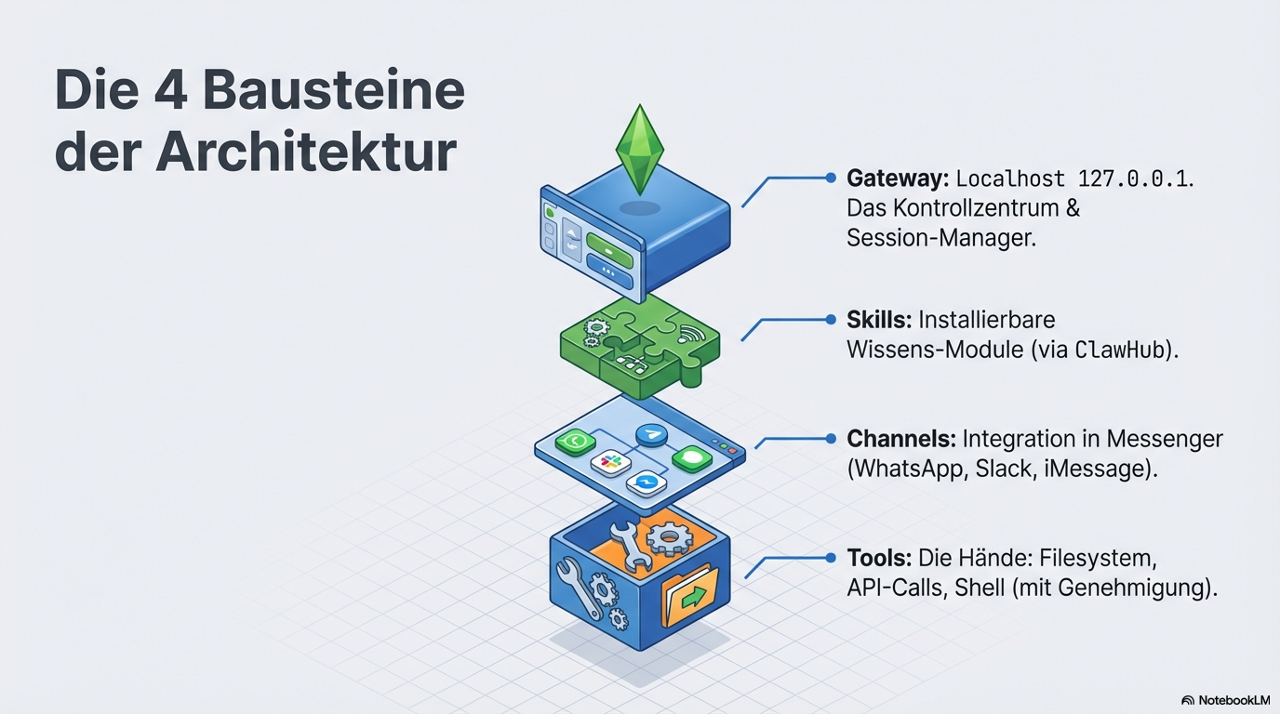
Das Gateway ist das Kontrollzentrum - ein dauerhaft laufender Prozess auf deinem Rechner (standardmäßig 127.0.0.1:18789), der das KI-Modell mit allem anderen verbindet. Er verwaltet deine Kanal-Verbindungen, hält Sessions aufrecht und teilt dem KI-Modell in Echtzeit mit, was es gerade tun kann. Konfiguration und Session-Zustand bleiben zwischen Neustarts erhalten.
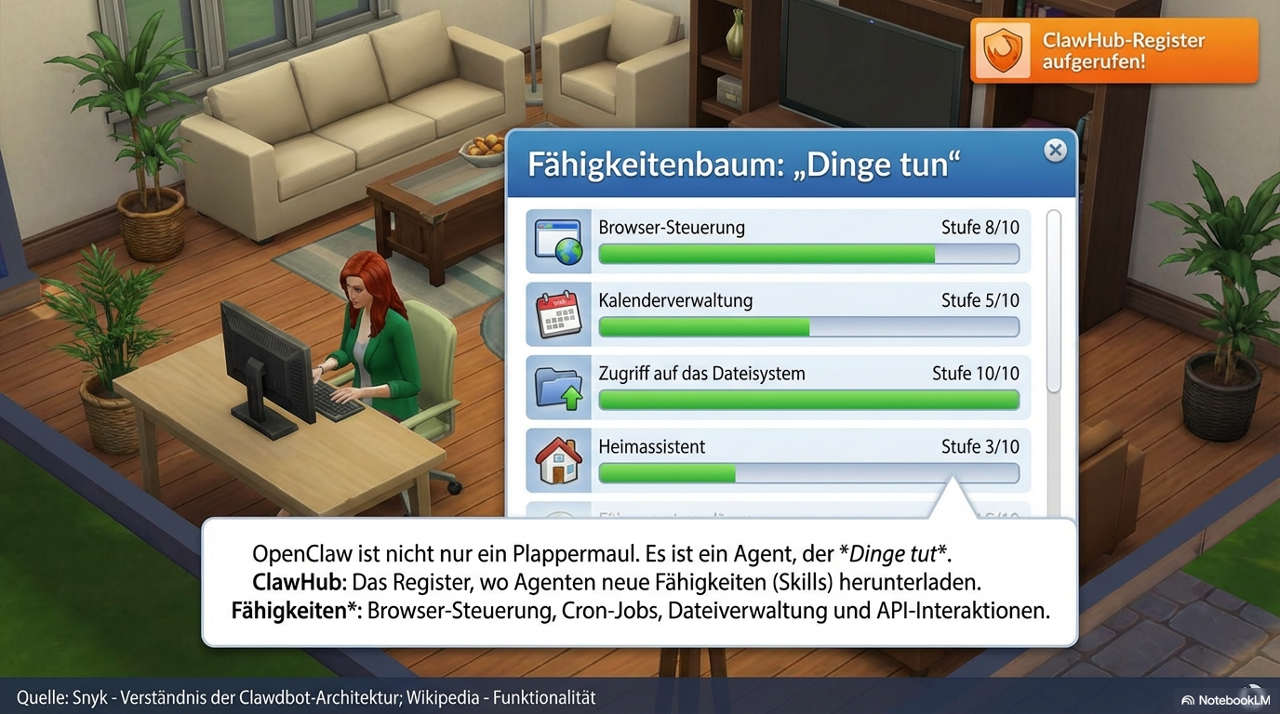
SKILLS sind die Wissens-Erweiterungen. Aus einer Community-Registry namens ClawHub kannst du Module installieren, die dem Agenten domänenspezifisches Verhalten beibringen. Skills sind auch die primäre Supply-Chain-Angriffsfläche (siehe Sicherheitsabschnitt unten).
Channels sind das Bindegewebe zur Außenwelt. Du interagierst nicht über eine neue App. Du schreibst dem Agenten über WhatsApp oder Slack oder iMessage - was auch immer du schon nutzt.
Tools sind die buchstäblichen Hände. Mit deiner Genehmigung kann der Agent Shell-Befehle ausführen, auf dein Dateisystem zugreifen, externe APIs aufrufen. Die tatsächlichen Berechtigungen variieren je nach Tool und Konfiguration (Host vs. Sandbox vs. Container).
Das, was niemand in den Einführungs-Posts erwähnt: Sicherheit - drei getrennte Risikoklassen
OpenClaws eigene Dokumentation nennt die Zugriffsebenen „spicy". Das ist eine ehrliche Einschätzung. Aber es ist wichtig, drei Risikoklassen zu trennen, die häufig vermischt werden:

1. Indirekter Prompt Injection - Dein Agent verarbeitet Inhalte, die er aus der Welt liest: E-Mails, Webseiten, Dokumente. Ein Angreifer kann versteckte Anweisungen in diesen Inhalten einbetten. Der Agent liest sie, interpretiert sie als legitime Befehle und handelt. Das ist ein generelles, noch nicht gelöstes Problem im Bereich KI-Agenten, das OpenClaw ausdrücklich in seinen Docs anspricht - ohne eine vollständige technische Lösung zu haben.
2. Exponierter Gateway / Token-Diebstahl (CVE-Klasse) - CVE-2026-25253 etwa betraf Token-Leakage durch eine automatisch aufgebaute WebSocket-Verbindung, wenn ein gatewayUrl-Parameter aus einem Query übernommen wurde. Das ist etwas anderes als Prompt Injection: eine Konfigurationslücke/Implementierungsschwachstelle, die einem Angreifer Gateway-Administratorzugriff verschaffen kann - ohne E-Mail, ohne Social Engineering. Mehrere CVEs wurden für spezifische OpenClaw-Versionen veröffentlicht.
3. Skills-Supply-Chain - Drittanbieter-Skills auf ClawHub sind Code. Über 400 Schad-Skills wurden gemeldet. OpenClaw reagierte mit einer VirusTotal-Partnerschaft zum Scannen von ClawHub-Einreichungen. Das ist das gleiche Supply-Chain-Risiko wie bei npm oder PyPI - außer dass diese Skills Zugriff auf deinen Rechner haben.
Das Team hat auf allen drei Fronten reagiert: Gateway bindet standardmäßig an localhost, Verbindungen erfordern Authentifizierungstoken, es gibt ein eingebautes Security-Audit-CLI mit --fix-Flag und ein veröffentlichtes Security-Threat-Modell. Die Risiken sind real und unterschiedlich. Es lohnt sich zu wissen, welches man mitigiert.

Für wen ist das gerade wirklich?
Ehrlich gesagt: Technische Nutzer und Entwickler, die verstehen, was sie einschalten - einschließlich welches Modell-Backend sie konfigurieren (und ob sie damit einverstanden sind, dass dieses Modell ihre Daten erhält), und welche Skills sie installieren.
Das ist noch kein „meine Großeltern können es installieren"-Produkt. Aber die Richtung ist für jeden relevant, der mit KI arbeitet. Wir bewegen uns von Tools, die Dinge erklären, zu Tools, die Dinge tun.
Die OpenClaw Foundation wurde im Februar 2026 gegründet, um das Projekt offen, modell-agnostisch und außerhalb der Kontrolle eines einzelnen Unternehmens zu halten.

Was als nächstes kommt
In den nächsten Beiträgen gehe ich tiefer auf:
- Warum es wirklich viral gegangen ist - die tatsächliche Mechanik hinter 2 Millionen Besuchern
- Moltbook - ein KI-exklusives soziales Netzwerk, das von jemand anderem unabhängig gebaut wurde
- Wie lokale KI-Agenten im Vergleich zu Cloud-KI in Bezug auf deine Daten abschneiden
- Prompt Injection für normale Menschen erklärt
- Open-Source-Alternativen, die Ähnliches tun

